 Applied research often has the clarifying effect of disabusing one of preconceived notions. Except perhaps for debates about religion where all bets are off for everyone on all sides at all times. But that’s another story.
Applied research often has the clarifying effect of disabusing one of preconceived notions. Except perhaps for debates about religion where all bets are off for everyone on all sides at all times. But that’s another story.
Every now and then I will post an article or a link to one on social media from some at least marginally reputable science site on some new wrinkle in theoretical time travel. I have three friends, in particular, located in British Columbia, Nunavut and Manitoba, who are sci-fi fans, but also science rationalists, who can be quickly counted on to let me know two things: what a fun idea the new theory is; how completely implausible it is on the science. Thanks, guys.
As a kid, while I enjoyed reading some science fiction – Ursula K. Le Guin‘s Lathe of Heaven from 1971, and Arthur C. Clarke’s 1953 book Childhood’s End, come immediately to mind – I was also fond of other genres, including Greek mythology (I remember taking a mighty tome home on the subject from my school library and reading it from start to finish one Sunday in Oshawa, where I learned a bit about the Hippoi Athanatoi). Time travel was just one topic within one genre of my reading interests back then.
But aside from my reading interests, in terms of my later popular culture viewing, on both the big and small screens, as well as my own writing from time-to-time, time has never been too far from my remote view, if I think broadly about it.
Both The Time Tunnel on ABC and Star Trek on NBC television series originally debuted within a day of each other in September 1966. I was nine. The Time Tunnel (https://www.tvyesteryear.com/shows/the-time-tunnel/), largely forgotten today, was about Project Tic-Toc, a top-secret U.S. government effort to build an experimental time machine, known as “The Time Tunnel” due to its appearance as a cylindrical hallway. The base for Project Tic-Toc is a huge, hidden underground complex in Arizona, 800 floors deep and employing more than 12,000 specialized personnel. Star Trek made its debut on Sept. 8, 1966, one day earlier then The Time Tunnel, and is far from forgotten.
Manu Saadia, a contributor for The New Yorker, wrote back in 2016 in “The Enduring Lessons of ‘Star Trek,”‘ a 50th anniversary piece to mark the debut of the franchise, that “the original series was at its best when its cast engaged in good, old-fashioned time travel. ‘The City on the Edge of Forever,’  penned by Harlan Ellison, threw the dynamic trio of Kirk, Bones, and Spock into nineteen-thirties New York. They were familiar characters dropped into a familiar setting, tasked with a familiar, if daunting, mission: save the world. (By a series of unlucky coincidences, their arrival in New York had altered the future, leading to Nazi Germany winning the Second World War. This had to be corrected.)” Joseph Walter of Screen Rant in his piece today, “Star Trek: The 10 All Time Best (And 10 Worst) Episodes, Officially Ranked” rates “The City on the Edge of Forever” as the sixth-best Star Trek episode from the entire franchise, which includes all the series that followed the original, which aired on NBC from September 1966 to June 1969.
penned by Harlan Ellison, threw the dynamic trio of Kirk, Bones, and Spock into nineteen-thirties New York. They were familiar characters dropped into a familiar setting, tasked with a familiar, if daunting, mission: save the world. (By a series of unlucky coincidences, their arrival in New York had altered the future, leading to Nazi Germany winning the Second World War. This had to be corrected.)” Joseph Walter of Screen Rant in his piece today, “Star Trek: The 10 All Time Best (And 10 Worst) Episodes, Officially Ranked” rates “The City on the Edge of Forever” as the sixth-best Star Trek episode from the entire franchise, which includes all the series that followed the original, which aired on NBC from September 1966 to June 1969.
Star Trek, and its many successors, both television series and movies, not surprisingly have continued to explore the idea of time travel and alternate timelines in all kinds of manifestations. I like many of them, but have a particular fondness for Dr. Beverly Picard, who in a briefly existing alternate timeline in “All Good Things,” the aptly-named May 23, 1994 final episode of Star Trek: The Next Generation, is the captain of the U.S.S. Pasteur (NCC-58925), as her ex-husband, Capt. Jean-Luc Picard, inexplicably finds his mind jumping between the present stardate 47988 and the past just prior to the U.S.S. Enterprise-D‘s first mission seven years earlier at Farpoint Station and then flash-forward 25 years into the future, where he has retired to the Picard family vineyard in Labarre, France.
In The Man in the High Castle, an alternate history novel by American writer Philip K. Dick, published and set in 1962, events takes place 15 years after a different end to the Second World War, and depict intrigues between the victorious Axis Powers – primarily, Imperial Japan and Nazi Germany – as they rule over the former United States, as well as daily life under totalitarian rule. A television series was loosely adapted from the book and ran for four seasons from January 2015 until last November.
In a similar vein, The Plot Against America is a novel by Philip Roth published in 2004. It is an alternate history in which Franklin D. Roosevelt is defeated in the presidential election of 1940 by Charles Lindbergh. Adapted for television as a six-part miniseries that aired in March and April, The Plot Against America imagined an alternate American history told through the eyes of a working-class Jewish family in Newark, New Jersey, as they watch the political rise of Lindbergh, an aviator-hero and xenophobic populist.
Wormholes and parallel universes are pretty much de rigueur for this genre, and Sliders, a television series which aired between 1995 and 2000, understood that, as it was premised on a group of travelers, led by Quinn Mallory, using a wormhole to “slide” between different parallel universes. Alternate timelines are altered versions of our timeline. Unlike parallel universes, alternate timelines do not seem to diverge from the universe, but instead rewrite history to the point of wiping out the original timeline.
For its first two seasons, Sliders was produced in Vancouver. It was filmed primarily in Los Angeles in the last three seasons.
In Quantum Leap, which aired on NBC for five seasons from March 1989 through May 1993, Scott Bakula stars as Dr. Sam Beckett, a physicist who leaps through spacetime during an experiment in time travel, by temporarily taking the place of other people to correct historical mistakes. Dean Stockwell co-stars as Admiral Al Calavicci, Sam’s womanizing, cigar-smoking companion and best friend, who appears to him as a hologram.
Time Changer is an independent science fiction Christian seriocomic film written and directed by Rich Christiano, and released by Five & Two Pictures in 2002. The screenplay concerns Dr. Norris Anderson (Gavin MacLeod), who uses his late father’s time machine to send his colleague, Bible professor Russell Carlisle (D. David Morin), from 1890 into the early 21st century.
The fascination with alternate timelines is not limited to science fiction writers. Historians have been known to wonder if the 1963 assassination of President John F. Kennedy, in ending Camelot, changed the course of history for the worse? It’s a popular, if not almost universal view, that it did. But historian David Hackett Fischer, in his 1970 book, Historians’ Fallacies: Toward a Logic of Historical Thought, warns of the dangers of counterfactual historiography, which extrapolates a timeline in which a key historical event did not happen or had an outcome which was different from that which did in fact occur. Had Kennedy lived would the United States have exited Vietnam closer to 1964 than 1975? Would Lyndon Johnson’s landmark Civil Rights Act of 1964 have passed so soon under JFK? We can only wonder.
In 1983, Ohio State University historian Stephen Kern wrote The Culture of Time and Space, 1880-1918, a book which talked about the sweeping changes in technology and culture that reshaped life, including the theory of relativity and introduction of Sir Sandford Fleming’s worldwide Standard Time – and an onrush of technics, including telephone, electric lighting, steamships, skyscrapers, bicycles, cinema, airplanes, X-rays, machine guns, as well as cultural innovations that shattered older forms of art and thought, such as the stream-of-consciousness novel, psychoanalysis, Cubism, simultaneous poetry. All of these things created new ways of understanding and experiencing time and space during that almost 40-year period ending with the end of the First World War. Kern’s argument is that in the modern preoccupation with speed, especially with the fast and impersonal telegraph, international diplomacy broke down in July 1914, leading to the outbreak of the First World War the following month.
In physics, according to Albert Einstein’s 1905 theory of special relativity (SR), motion in space alters the flow of time, creating a time dilation, speeding up or slowing down time, because as you move through space, time itself is measured differently for the moving object than the unmoving object. This, in theory, would allow time travel within the known laws of physics into the future, not into the past (https://soundingsjohnbarker.wordpress.com/2016/03/12/time-dilation-daylight-saving-time-and-other-mysteries-of-time/).
Standard Time, of course, with its standardized times zones, is a Canadian invention, courtesy of Sir Sandford Fleming, who conveniently divided time into hourly segments, dating back to October 1884 and the International Prime Meridian Conference attended by 25 nations in Washington, D.C. Before Fleming invented standard time, noon in Kingston, Ontario was 12 minutes later than noon in Montréal and 13 minutes before noon in Toronto. Noon local time was the time when the sun stood exactly overhead.
Most of Canada’s time experts work in a place called Building M-36 (which involuntarily conjures up for me visions of the X-Files and Area 51.) They work in the Frequency and Time program in the Measurement Science and Standards portfolio with the National Research Council of Canada on Montreal Road in Ottawa. Physicist Rob Douglas, the principal research officer, however, can be found on Saskatchewan Drive in Edmonton.
Fleming’s genius was to create 24 time zones and within each zone the clocks would indicate the same time, with a one-hour difference between adjoining zones. Usually, when one travels in an easterly direction, a different time zone is crossed every 15 degrees of longitude, which is equal to one hour in time (https://soundingsjohnbarker.wordpress.com/2015/03/07/just-remember-you-are-about-to-pass-briefly-through-the-twilight-zone-nothing-can-happen-tomorrow-between-201-a-m-and-259-a-m-because-those-59-minutes-do-not-exist-on-march-8/). Like many things, there are, of course, exceptions. Samoa uses Coordinated Universal Time (UTC+13:00) as standard time and UTC+14:00 as daylight saving time, which it observes during summer in the southern hemisphere. The U.S. territory of American Samoa, as well as the Midway Islands and the uninhabited islands of Jarvis, Palmyra, and Kingman Reef, use the Samoa Time Zone, which observes standard time by subtracting eleven hours from Coordinated Universal Time (UTC-11). The zone is one hour behind the Hawaii-Aleutian Time Zone, one hour ahead of Howland and Baker islands, and 23 hours behind Wake Island Time Zone.
Samoa happens to sit in the middle of the Pacific Ocean, just 32 kilometres, or 20 miles, east of the International Date Line, an imaginary line at the 180º line of longitude that runs from the South Pole to the North Pole separating two consecutive calendar days. Immediately to the left of the International Date Line the date in the Eastern Hemisphere is always one day ahead of the date (or day) immediately to the right of the International Date Line in the Western Hemisphere (https://soundingsjohnbarker.wordpress.com/2014/09/29/skip-a-day-why-not-samoa-did/).
It is not a perfectly straight line, however, and has been moved slightly over the years to accommodate needs of varied countries in the Pacific Ocean. Kiribati, north of Samoa and near the equator, south of Hawaii, previously straddled the dateline. The eastern part of Kiribati was a whole day and two hours behind the western part of the country where its capital is located and a time difference of 23 hours between neighbouring islands. There were nine islands on the eastern side of the international date line, and 20 per cent of the population. On Jan. 1, 1995 it added an eastward extension to its section of the dateline so all 33 of its islands would have the same date and all of Kiribati would be in the Eastern Hemisphere.
Since 1892, when Samoa had two Monday, July 4ths, it had been east of the International Date Line until Dec. 29, 2011, after switching sides to coincide its days better with trading partners in the United States and Europe. Now, Samoa does a lot more business with New Zealand, Australia, China and Pacific Rim countries such as Singapore, so it switched back to the western side of the International Date Line.
China, which has just one time zone – Beijing Standard Time – making the time zone uncommonly wide. In Kashgar, in the extreme western part of China, the sun is at its highest point at 3 p.m. and in the extreme eastern part at 11 a.m. In 1912, the year after the collapse of the Qing Dynasty, the Republic of China had created five time zones in the country, ranging from five and a half to eight and a half hours past Greenwich Mean Time. But in 1949, as the Communist Party consolidated control of the country, Chairman Mao Zedong ordered that all of China use Beijing time.
Historians aren’t the only academics to ponder these sort of things.
Massachusetts Institute of Technology (MIT) professor of philosophy Bradford Skow suggests a “box” universe theory, as describes “now” as an arbitrary place in time and states that the past, the future and the present all exist simultaneously, suggesting that if we “look down” on the universe, as if we were looking at a piece of paper, we would see time spanning all directions, exactly the same way that we see space at some point. I believe my three friends unanimously concluded this was rather bunk, but good fun.
You can also follow me on Twitter at: https://twitter.com/jwbarker22
55.742943
-97.844475



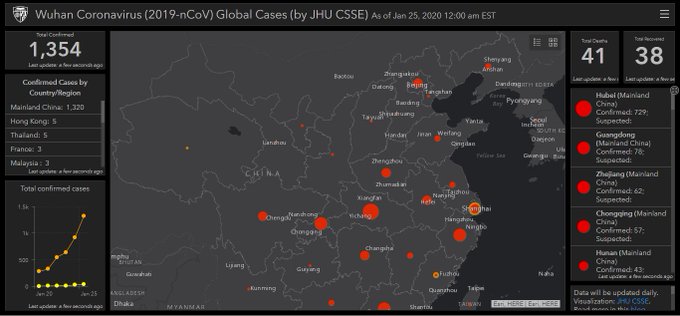
 While some 675,000 Americans died over three years between January 1918 and December 1920 during the three waves of the Spanish Flu pandemic, the country’s population was 103.2 million. Today, the population of the United States is more than 331 million. The world population in 1918 was about 1.8 billion, compared to about 7.8 billion people today.
While some 675,000 Americans died over three years between January 1918 and December 1920 during the three waves of the Spanish Flu pandemic, the country’s population was 103.2 million. Today, the population of the United States is more than 331 million. The world population in 1918 was about 1.8 billion, compared to about 7.8 billion people today.
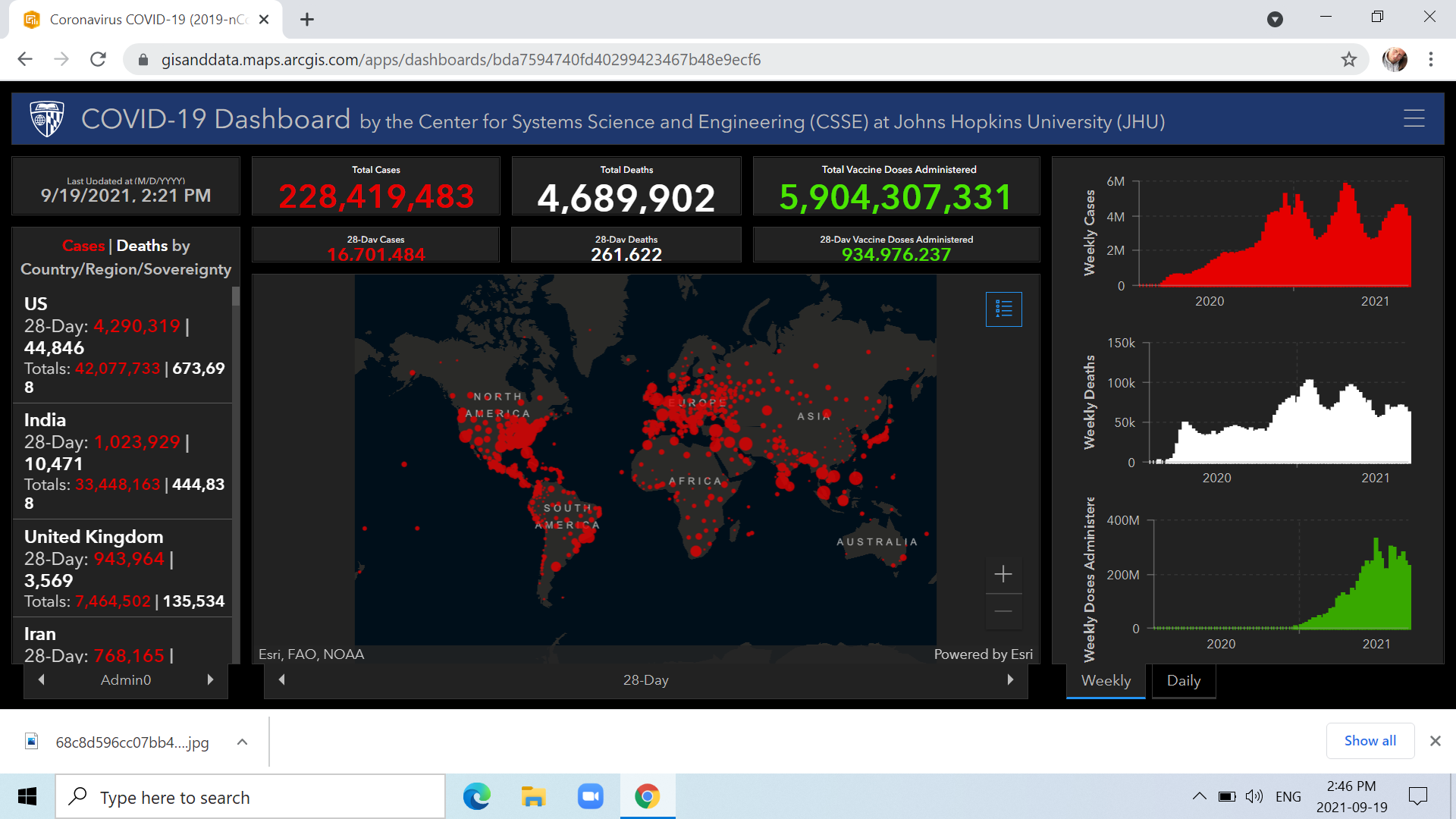
 The rolling real time daily death count on the online COVID-19 Dashboard by the Center for Systems Science and Engineering (CSSE) at Johns Hopkins University (JHU) in Baltimore functions as our equivalent of the Bulletin of the Atomic Scientists’ “Doomsday Clock,” circa 1947, and the clock itself, set at 100 seconds before midnight last Jan. 27, is being profoundly influenced by COVID-19.
The rolling real time daily death count on the online COVID-19 Dashboard by the Center for Systems Science and Engineering (CSSE) at Johns Hopkins University (JHU) in Baltimore functions as our equivalent of the Bulletin of the Atomic Scientists’ “Doomsday Clock,” circa 1947, and the clock itself, set at 100 seconds before midnight last Jan. 27, is being profoundly influenced by COVID-19.





